- De
- En

Language and text-based research data are of outstanding importance in many disciplines in the humanities. Initially with the data domains Collections, Lexical Resources and Editions, Text+ addresses the requirements of a wide range of research fields that are based on a long research tradition. These data domains are linked to mature methodological paradigms that require distinctive, but also cross-disciplinary data generation, curation, and data management practices.
Text+ is not limited to existing data, but will systematically expand its portfolio in close consultation with the expert communities involved. This also includes tools to support researchers in the FAIR creation, use and provision of data throughout the entire research data life cycle.
The usability of the data and tools combined with the legally compliant use of language and text data, which often affects the rights of third parties, are central tasks of Text +. The diversity of the data adds to the complexity, the data being heterogeneous in terms of language families (extending beyond Europe), modalities of language and writing systems. The + sign indicates that Text+ is open, for example also for language-based resources and tools for speech and for multimodal data. As a distributed infrastructure, Text+ relies on and incorporates a wide range of existing data and tools from the currently more than 30 partners in the consortium.
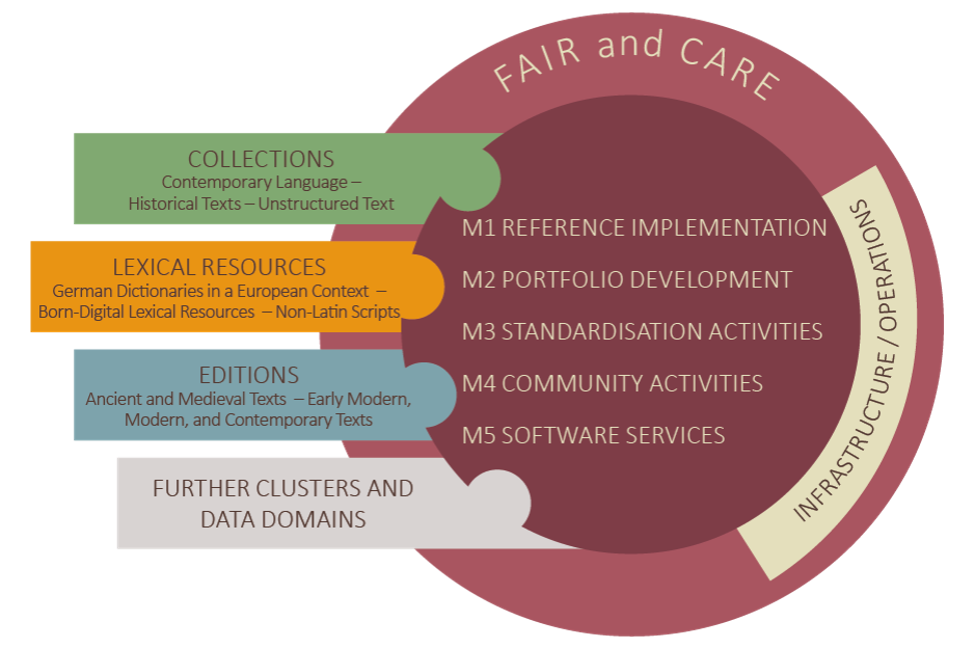
The GWDG is involved in the Network Infrastructure/Operations task area. The GWDG contributes competencies in the field of Authentication Authorization Infrastructure (AAI) and Persistent Identifiers (PID) to Text+ and develops them further.
The Text+ consortium consists of several institutions. You will find an overview on the NFDIs Text+ webpage.
01.10.2021 - 30.09.2026
![]() Project grant: 460033370
Project grant: 460033370

